Programming Languages and Databases
- Python for data science.
- Python, JavaScript, Php, Java and Dart.
- Web Scraping with Python.
- SQL for data extraction.
- SQLite, MySQL and MongoDB databases.
In this web page I demonstrate my skills in order to solve business problems, using Data
Science tools and knowledge, through public data projects. You will also find here a bit of
my story, professional experiences, tools and skills related to Data Science.
Feel free to get in touch with me through the links at the top and
bottom of the page.

My main goal is to build data-based products, developed with Machine Learning and/or Data Analytics skils to solve real-world business problems, generating profit and reducing costs.
As a Data Scientist, my latest job was to create a Machine Learning solution to predict estimated value of sales for the next 6 weeks for a pharmacy chain in Europe. The trained Regression algorithm had 10% of MAPE (error metric) and was made available for queries through a Telegram bot.
At Velty, I was personally responsible for building the company's institutional website. In addition to contributing, as a team, to building projects ranging from ecommerce to B2B systems, understanding the business model from companies and creating software based solutions for their demands. I was actively working with tools like Php, JavaScript, SQL, and Git, always using agile methodologies on a daily basis to menage the workflow.
As a professional, I have always strived to learn enough skills to become an independent Data Scientist, capable of building end-to-end projects within the data science pipeline, ranging from data extraction to designing ML models and putting them into production.
At this point in my career, I feel confident to work as a Data Scientist, so that I can create value by using my knowledge in Python, Statistics, Machine Learning, Storytelling as well as other tools, in order to build data solutions that can solve companies' problems.
Analytical Tools: SQL, Numpy, Matplotlib, Seaborn, Scipy, Pandas and Plotly. Development Tools: Python, Php, JavaScript, Git, Scrum, Basic Docker and Linux. Pipeline Tools: MySQL, Postgres, SQL Server and MongoDB.
The Comunidade DS is an educational institution that provides an environment for developing data projects for business problems, close to the real challenges of companies. These projects are carried out individually by each professional, using public data and developing the problem from the conception of the business challenge to the implementation of the algorithm in production, through Cloud Computing tools.
As a Data Scientist, I have been developing projects in the community since August 2022 and the works produced are described in detail in the 'Projects' section.
Professional experience in the position of Full-Stack Web Developer, where I could practice my knowledge in the following tools: git, gitlab, php, javascript, html, css, nodejs, sql, mongodb, laravel, and etc. I was also responsible many times for the entire pipeline of a project, from the creation of front-end, to database management and server logic. Also dealing with customer service, requirements gathering and presentations.
Solving business problems that are close to real problems at various companies, using Data Science skills and publicly available data. These solutions possess all main steps a Data Science solution should have: understanding the business problem, collecting and cleaning data, feature engineering, going through exploratory data analysis, data preparation, feature selection, machine learning modeling, model evaluation, as well as translating model performance to financial and business results. Finally, deploying the final product by using a Cloud Computing tool.
I have successfully graduated from the Deep Learning Nanodegree and the Machine Learning & AI Foundations Nanodegree from Udacity and also, more recently I became a certified Data Scientist by Datacamp. In all courses I was evaluated with practical projects that recreated real-world challenges involving data, applying the techniques and knowledge learnt throughout the courses.

In this project I used Python, Flask and Regression Algorithms to predict Rossmann sales, a drug store chain, six weeks in advance. Reason being Rossmann CEO needs to determine the best resource allocation for each store renovation. The final solution is a Telegram Bot that returns a sales prediction of any given available store number, with the possibility of being accessed from anywhere.

In this project, I solved a business case for Billion Bank, a fictional digital bank in Brazil that works with digital accounts and credit cards. When a customer requests an increase in their credit card limit, the bank consults a third-party credit company which returns a recommendation of "deny" or "approve". The process was slow and expensive, so they "hired" a data science team to create an internal credit evaluation model specific to the bank.
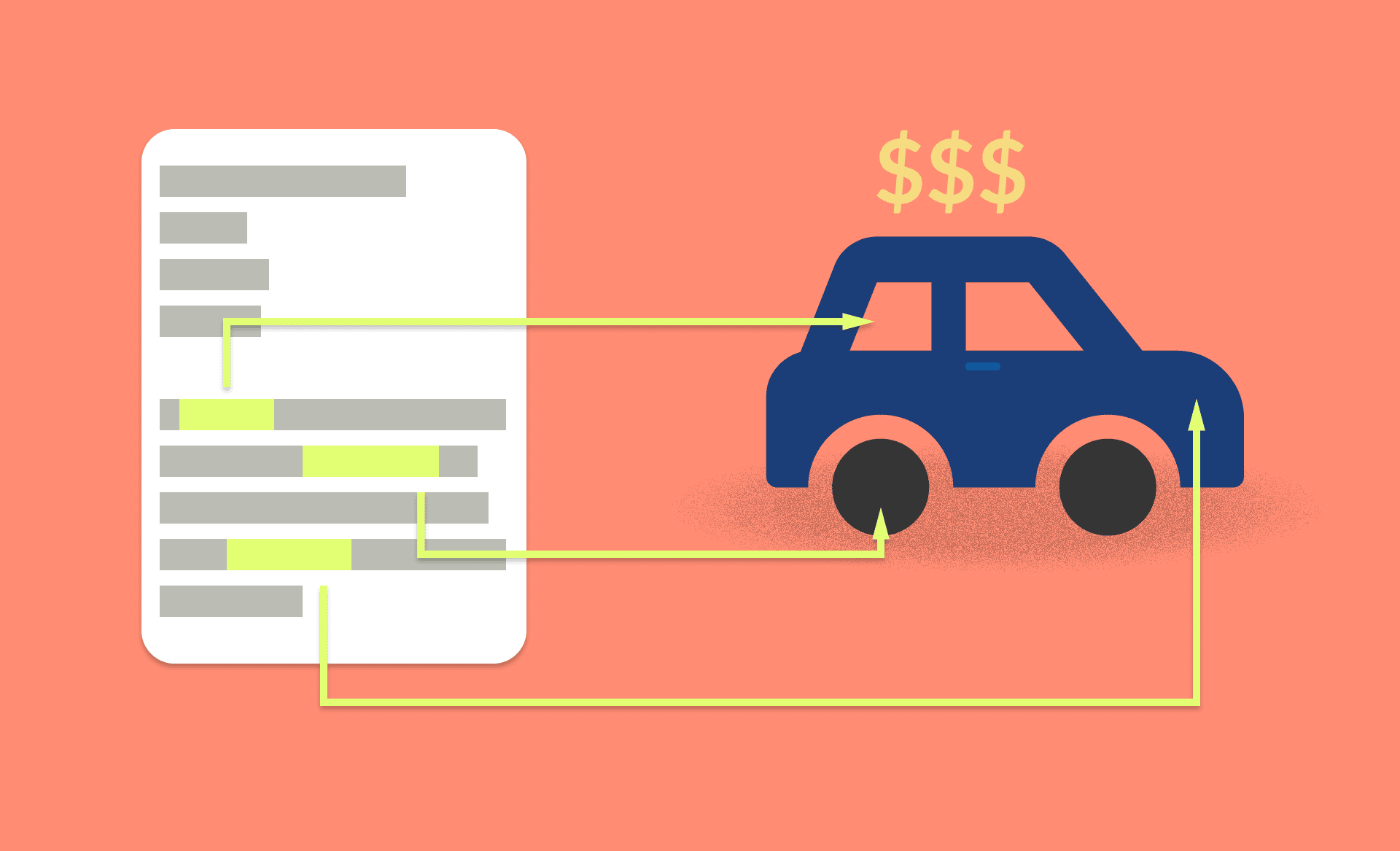
This project was developed by me and my group during Hackday #2, a hackathon organized for DS Community students. In order to solve this business problem, we had to develop a model to predict the price of a used car based on its characteristics, in order to help decision-making in the pricing of the car when the company is going to resell it after the end of its lifecycle.

This project accepts any user-supplied image as input. If a dog is detected in the image, it will provide an estimate of the dog's breed. If a human is detected, it will provide an estimate of the dog breed that is most resembling. In this real-world setting, I pieced together a series of models to perform different tasks; for instance, the algorithm that detects humans in an image will be different from the CNN that infers dog breed.

This is a Time-Series forecasting project, where I dealt with historical data from a real-world company called Cyclo Hop, whose business model consists of renting bicycles around the American major cities, and had the business problem of not finding the best total number of bicycles to keep in their stock throughout the year. For this project I created a neural network trained on historical data to make predictions about the optimal number of bicycles for the company to have over time.

In this data engineering project I used Python, Web Scraping and PostgresSQL to create an ETL process for Star Jeans, a fictitious company. Star Jeans' owners in order to better understand the USA male's jeans market and learn how to enter it, they hired a Data Science/Engineering team to gather information regarding H&M. The built solution is an ETL that extracts data from H&M website, cleans it, and saves it to a PostgreSQL database on a weekly basis. Then, it adds and displays the data with filters in a Streamlit App, where it can be accessed from anywhere by Star Jeans' owners.
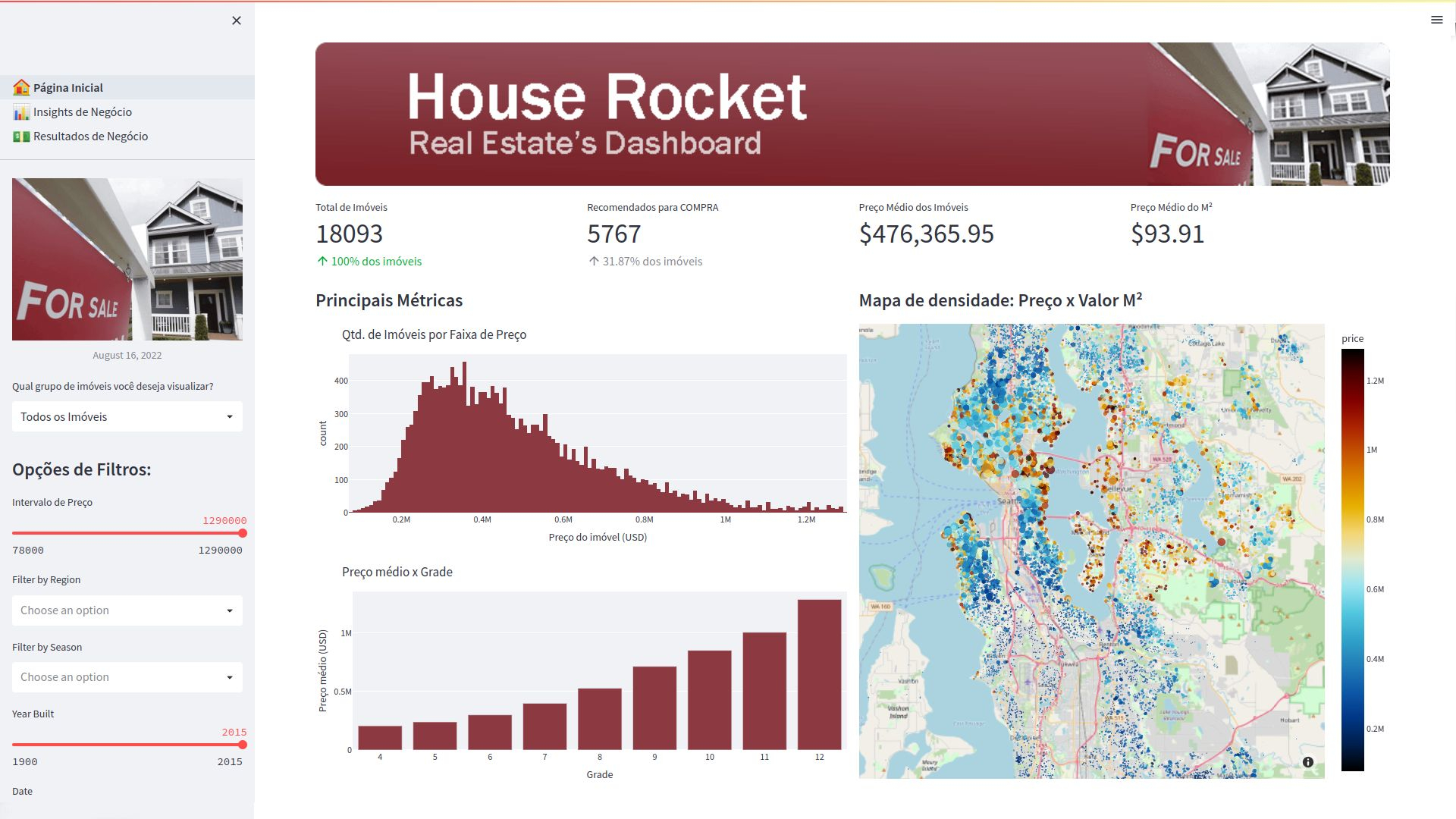
In this insights project I used Python and Streamlit to solve a profit maximization problem for House Rocket, a fictitious real estate company, by suggesting whether a property should or shouldn't be bought and resold. If this feasible solution strategy were applied the total obtained profit would be around US$ 473 million, with an average profit of 45 thousand dollars per property.
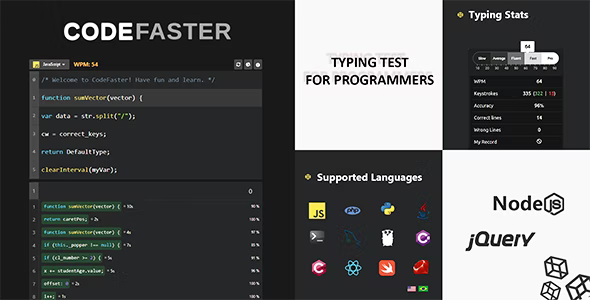
A gamified typing tool for programmers who want to increase their typing speed at coding and serve as a first time experience with the syntax of new programming languages. It also shows a personalized Dashboard with the user's performance metrics throughout the more than 5 games available in the website.

A tool for students during class to take screenshots of the blackboard and save it in a place to not lose them later. For example, if it is a important concept or the resolution of a math problem, just take a photo of it and save on GalleryNote with proper label, description, subject and notes, then you can referrer to it at ease.
Thanks for reading and feel free to get in touch.