Linguagem de Programação e Banco de Dados
- Python for Data Science.
- Python, JavaScript, php, Java e Dart.
- Web Scraping with Python.
- SQL for data extraction.
- Database SQLite, MySQL e MongoDB.
Nessa página, eu demonstro minhas habilidades de resolver problemas de negócio utilizando
conceitos e ferramentas da Ciência de Dados, através de projetos com dados públicos. Você
vai encontrar também, minhas experiências profissionais, habilidades, ferramentas e
conceitos envolvendo a Ciência de Dados.
Sinta-se à vontade para entrar em contato
comigo através dos links no final da página.

Meu objetivo principal é construir produtos baseados em dados, desenvolvidos com técnicas de Machine Learning ou Estatística para solucionar os problemas de negócio das empresas, gerando lucro e reduzindo custos.
Como Cientista de Dados, meu último trabalho foi o de gerar uma lista de imóveis que representasse os melhores negócios possíveis para uma imobiliária, tendo como base um conjunto de dados de imóveis que compunha o portfólio da empresa. Utilizei de ferramentas de visualização de dados e storytelling para criar apresentações dos principais KPI’s do modelo de negócio da empresa e do lucro estimado da compra e revenda dos imóveis contidos na lista ordenada, que representou um lucro de cerca de17% com relação ao capital investido inicialmente para a compra dos imóveis.
Na Velty, eu fui pessoalmente responsável pela construção do site institucional da empresa. Além de contribuir, em time, na construção de projetos que envolviam desde ecommerces até sistemas B2B, entendo o modelo de negócio dos clientes e criando soluções de software para suas demandas. Trabalhei ativamente com ferramentas como Php, JavaScript, SQL, e Git, sempre utilizando-se de metodologias ágeis no dia-a-dia.
Como um profissional, eu sempre me esforçei para aprender as habilidades suficientes para me tornar um Cientista de Dados independente, capaz de construir projetos end-to-end dentro da pipeline de projetos da área Dados, desde a extração dos dados até a concepção de modelos de ML e pô-los em produção.
Neste ponto da minha carreira, eu me sinto confiante sobre minha capacidade de contribuir para impulsão dos resultados da empresa, utilizando de minhas expertises na construção de soluções com dados, e portanto, me sinto capaz para ingressar na indústria como um profissional de Dados.
Ferramentas Analíticas: SQL, Numpy, Matplotlib, Seaborn, Pandas, Plotly. Ferramentas de Desenvolvimento: Python, Php, JavaScript, Git, Scrum e Linux. Ferramentas de Pipeline: MySQL, Postgres, SQL Server, MongoDB.
A Comunidade DS é uma instituição educacional que fornece um ambiente para desenvolvimento de projetos de dados focados na solução de problemas de negócios, próximo aos desafios reais das empresas. Estes projetos são realizados individualmente por cada profissional, usando dados públicos e desenvolvendo o problema da concepção do desafio de negócio até a implementação do algoritmo em produção, através de ferramentas de computação em nuvem.
Como Cientista de Dados, eu venho desenvolvendo projetos na comunidade desde agosto de 2022 e os trabalhos produzidos são descritos em detalhes na seção seguinte.
Experiência profissional na posição de Desenvolvedor Web Full-Stack, onde pude praticar meus conhecimentos nas ferramentas git, gitlab, php, javascript, html, css, nodejs, sql, mongodb, laravel, e etc. Sendo responsável por diversas vezes de toda a pipeline de um projeto, desde a criação do front-end, até o gerenciamento do database e lógica do servidor. Além de lidar também com atendimento ao cliente, levantamento de requisitos e apresentação de resultados.
Construção de soluções de dados para problemas de negócio, próximos dos desafios reais das empresas, utilizando dados públicos de competições de Ciência de Dados, onde eu abordei o problema desde a concepção do desafio de negócio até a publicação do algoritmo treinado em produção, utilizando ferramentas de Cloud Computing.
Finalizei com sucesso os Nanodegree Fundamentos de IA & Machine Learning e Nanodegree Deep Learning da instituição educacional Udacity. Em ambos os cursos eu fui avaliado com projetos práticos que recriam desafios reais envolvendo dados, aplicando na solução as metodologias e práticas durante os cursos. Mais recentemente também finalizei a trilha de cursos Data Scientist do Datacamp.

In this project I used Python, Flask e Regression Algorithms to predict Rossmann sales, a dNeste projeto, eu usei Python, Flask e Algoritmos de Regressão para prever as vendas da cadeia de lojas de medicamentos Rossmann, com seis semanas de antecedência. Isso é necessário pois o CEO da Rossmann precisa determinar a melhor alocação de recursos para cada reforma de loja. A solução final é um Bot do Telegram que retorna a previsão de vendas de qualquer número de loja disponível, com a possibilidade de ser acessada de qualquer lugar.

Neste projeto, resolvi um caso de negócios para o Billion Bank, um banco digital fictício no Brasil que trabalha com contas digitais e cartões de crédito. Quando um cliente solicita aumento em seu limite de cartão de crédito, o banco consulta uma empresa de crédito terceira que retorna uma recomendação de "negar" ou "aprovar". O processo era lento e caro, então eles "contrataram" uma equipe de ciência de dados para criar um modelo de avaliação de crédito interno específico para o banco.
Este projeto foi desenvolvido por mim e pelo meu grupo durante o Hackday #2, um hackathon organizado para os estudantes da Comunidade DS. Para resolver este problema de negócios, tivemos que desenvolver um modelo para prever o preço de um carro usado com base em suas características, a fim de ajudar na tomada de decisão no preço do carro quando a empresa vai revendê-lo após o fim de sua vida útil.

Este projeto aceita qualquer imagem fornecida pelo usuário como entrada. Se um cachorro for detectado na imagem, ele fornecerá uma estimativa da raça do cachorro. Se um ser humano for detectado, ele fornecerá uma estimativa da raça de cachorro que é mais semelhante. Neste cenário real, eu juntei uma série de modelos para realizar tarefas diferentes; por exemplo, o algoritmo que detecta seres humanos em uma imagem será diferente da CNN que raça de cachorro.

This is a Time-Series forecasting project, where I dealt with historical data from a real-world company called Cyclo Hop, whose business model consists of renting bicycles around the American major cities, e had the business problem of not finding the best total number of bicycles to keep in their stock throughout the year. For this project I created a neural network trained on historical data to make predictions about the optimal number of bicycles for the company to have over time.

Neste projeto de engenharia de dados, eu utilizei Python, Web Scraping e PostgresSQL para criar um processo ETL para a Star Jeans, uma empresa fictícia. Os proprietários da Star Jeans, a fim de melhor entender o mercado de jeans masculinos nos EUA e aprender a entrar nele, contrataram uma equipe de Ciência de Dados/Engenharia para coletar informações sobre a H&M. A solução construída é um ETL que extrai dados do site da H&M, os limpa e os salva em uma base de dados PostgreSQL em um intervalo semanal. Em seguida, adiciona e exibe os dados com filtros em um aplicativo Streamlit, onde pode ser acessado de qualquer lugar pelos proprietários da Star Jeans.
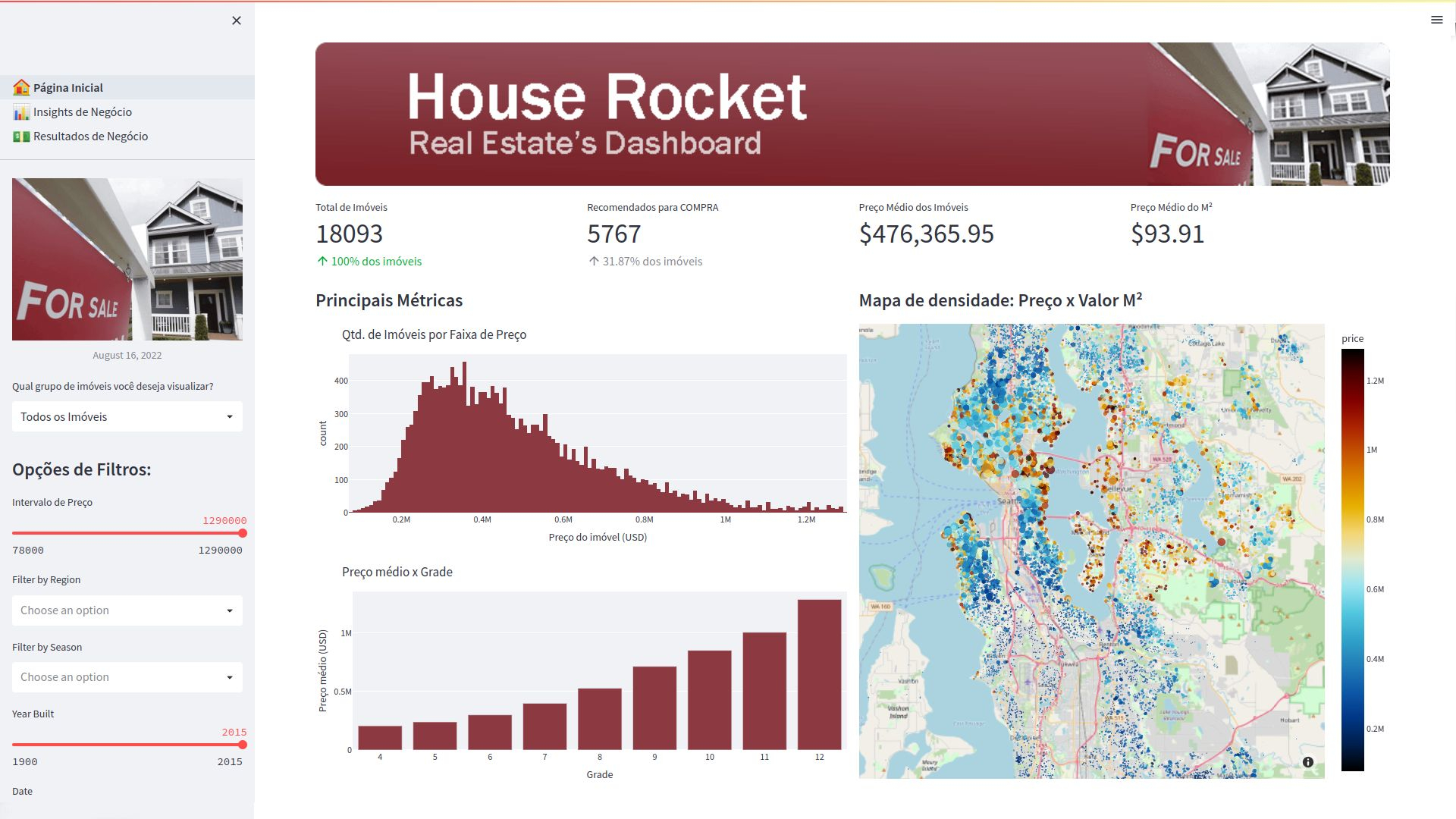
Neste projeto de engenharia de dados, eu utilizei Python, Web Scraping e PostgresSQL para criar um processo ETL para a Star Jeans, uma empresa fictícia. Os proprietários da Star Jeans, a fim de melhor entender o mercado de jeans masculinos nos EUA e aprender a entrar nele, contrataram uma equipe de Ciência de Dados/Engenharia para coletar informações sobre a H&M. A solução construída é um ETL que extrai dados do site da H&M, os limpa e os salva em uma base de dados PostgreSQL em um intervalo semanal. Em seguida, adiciona e exibe os dados com filtros em um aplicativo Streamlit, onde pode ser acessado de qualquer lugar pelos proprietários da Star Jeans. Neste projeto de análise de dados, utilizei Python e Streamlit para resolver um problema de maximização de lucro para a House Rocket, uma empresa imobiliária fictícia, sugerindo se uma propriedade deve ou não ser comprada e revendida. Se esta estratégia de solução viável fosse aplicada, o lucro total obtido seria em torno de US$ 473 milhões, com um lucro médio de 45 mil dólares por imóvel.
Uma ferramenta de digitação gamificada para programadores que desejam aumentar sua velocidade de digitação na codificação e servir como uma primeira experiência com a sintaxe de novas linguagens de programação. Apresenta também um Dashboard personalizado com as métricas de performance do usuário ao longo dos mais de 5 jogos disponíveis no site.

Uma ferramenta para que os alunos possam tirar screenshots do quadro-negro durante a aula e salvá-los em um lugar seguro, para que não sejam perdidos mais tarde. Por exemplo, se for um conceito importante ou a resolução de um problema matemático, basta tirar uma foto e salvar no GalleryNote com as etiquetas, descrições, assunto e notas adequadas, para que se possa consultar com facilidade.
Obrigado pela atenção e sinta-se à vontade para entrar em contato.